一、ganglia之web界面使用
上篇文章中,我们已经搭建起来了ganglia,如果正常,那么就可以在ganglia的web上看到gmond收集到的数据了,下面就来看下如何使用ganglia的web。
gweb由Main、Search、Views、Aggregate Graphs、Compare Hosts、Events、Reports、Automatic Rotation、Live Dashboard、Cubism、Mobile这些选项卡组成,用户可以快速查看所需信息。
1、全局网格视图
网格grid是所有集群的集合,在这个grid全局视图中,可以看到每个集群的的图形信息,grid是可用视图中的最高层视图。全局视图如下图所示: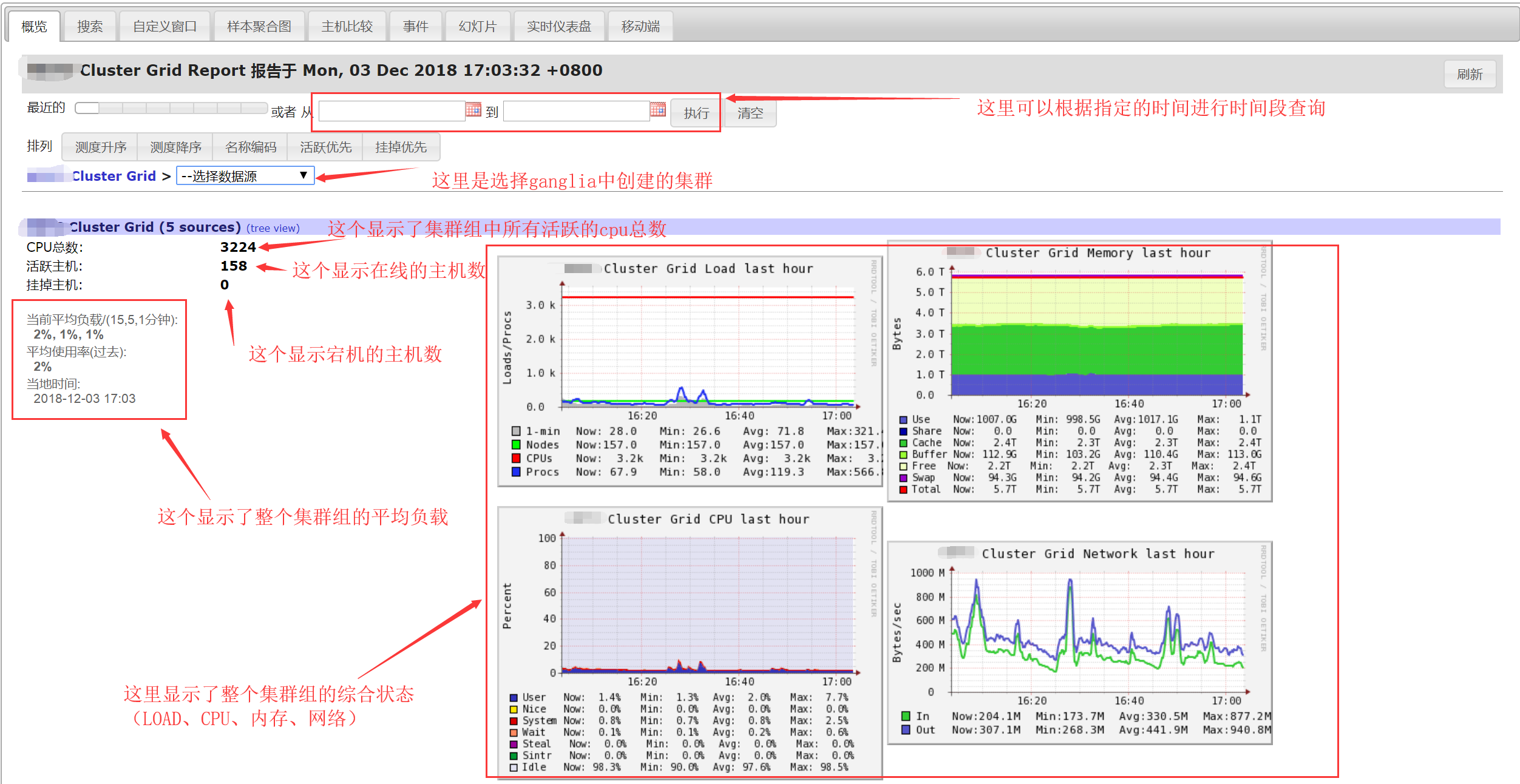
2、集群视图和物理视图
集群视图是某个集群的图形展示,其实集群是许多gmond推送过来数据的集合,集群视图顶部显示了整个集群的综合数据统计。可以在集群视图中快速查看每个主机的各种数据(默认收集cpu、内存、磁盘、网络、load、等信息)。请看下面截图: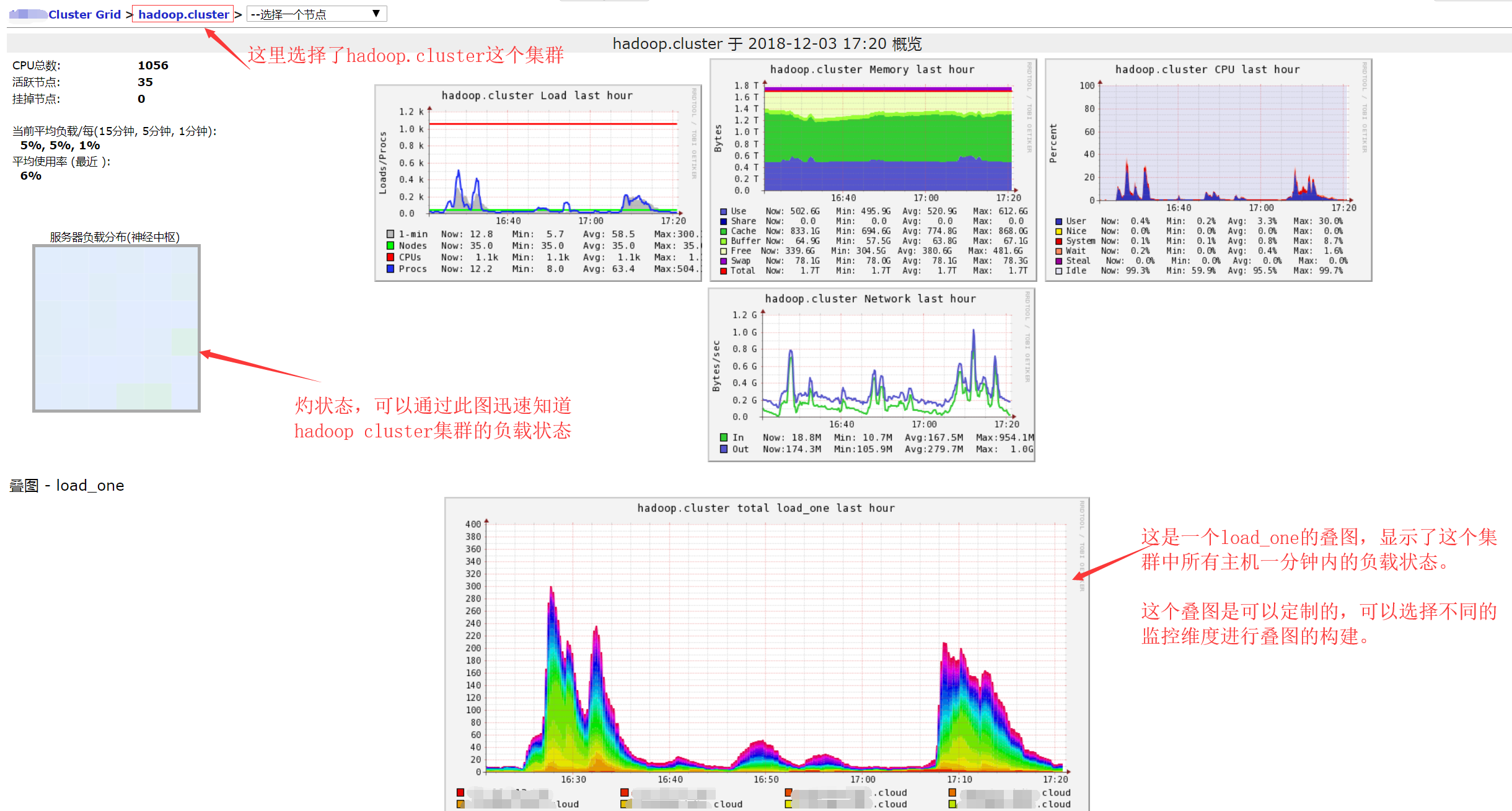
上图只是显示了集群视图一半的内容,下图显示了集群另一半内容:
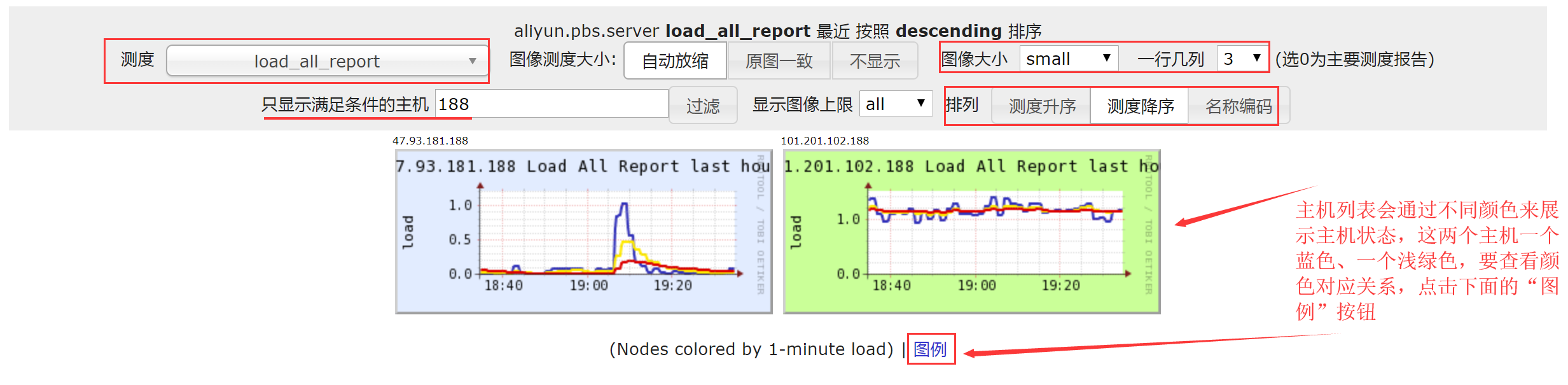
在这个界面中,可以选择要查看的监控数据指标,还可以通过关键字来过滤需要查看的监控数据指标,另外对图形的展示方式(大小、排列方式)都可以进行定制显示。可以看到,ganglia web可以非常方便的对集群所有主机的状态进行综合、整体查看,有助于了解集群整体运行状况。
此外,ganglia对集群下每个主机的负载通过不同的颜色进行标识,点击上图的“图例”可以查看每个颜色代表的负载等级,如下图所示:

如果集群某节点显示红色或者橙色,那么就需要注意了,此节点可能负载较高,需要检查是什么原因导致的负载升高。
下面再看一下集群的物理视图,在集群视图的右上角点击“查看物理状态”,如下图所示:
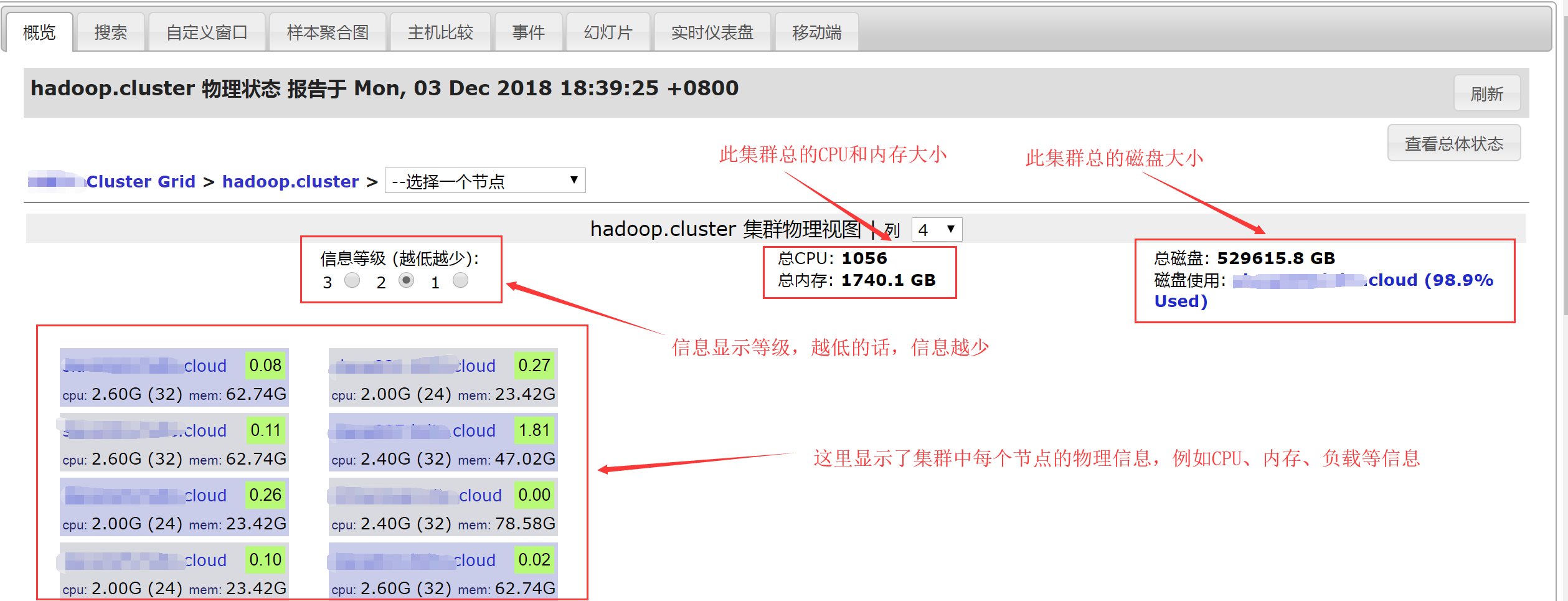
在上图中随便挑选一台主机,点击进入,进入某台主机的物理视图界面,如下图所示:
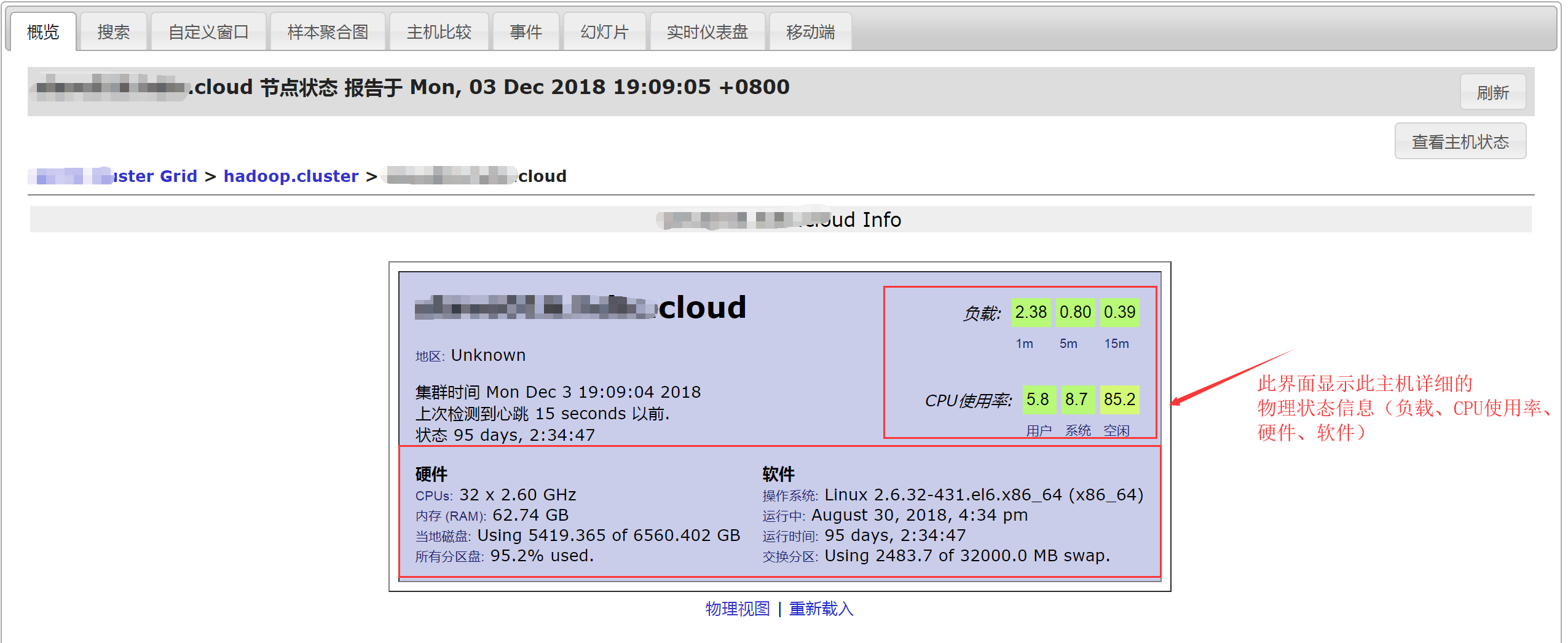
3、主机视图
点击上图右上角“查看主机状态”回到主机视图界面。这个界面展示了某台主机的主机视图信息,如下图所示:
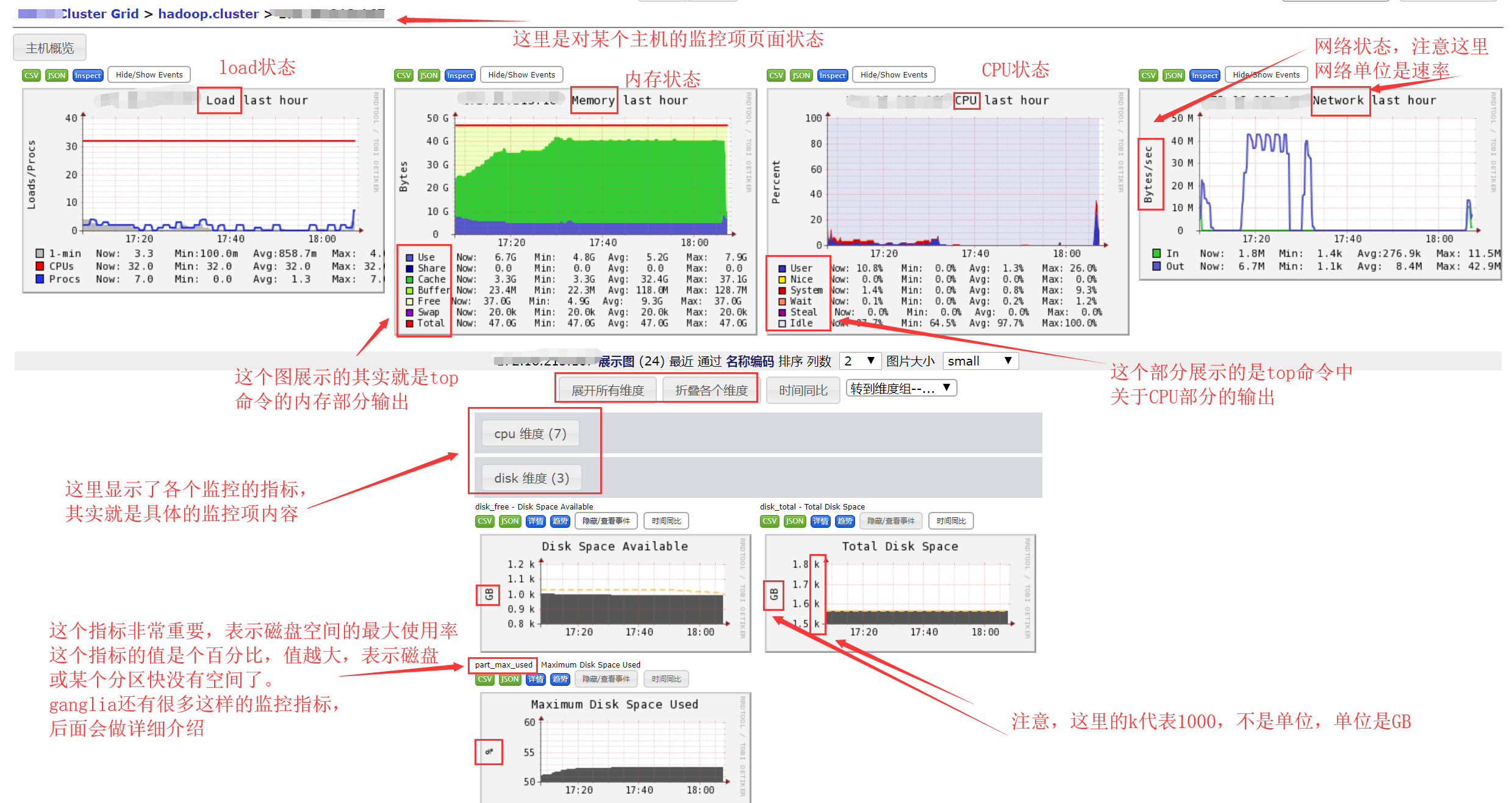
这个界面中是针对某个主机监控数据的详细汇总,最上面的图形仍然是默认的汇总图(load、内存、CPU、网络),而在下面显示了此主机其它监控指标,例如disk、process维度、cpu维度等,这些监控指标都是ganglia默认自带的,当然,我们也可以构建自己需要的监控指标,这就是扩展ganglia监控,后面马上会介绍到。
在上图中点击任意一个监控指标,即可查看更详细的监控状态数据,如下图所示:
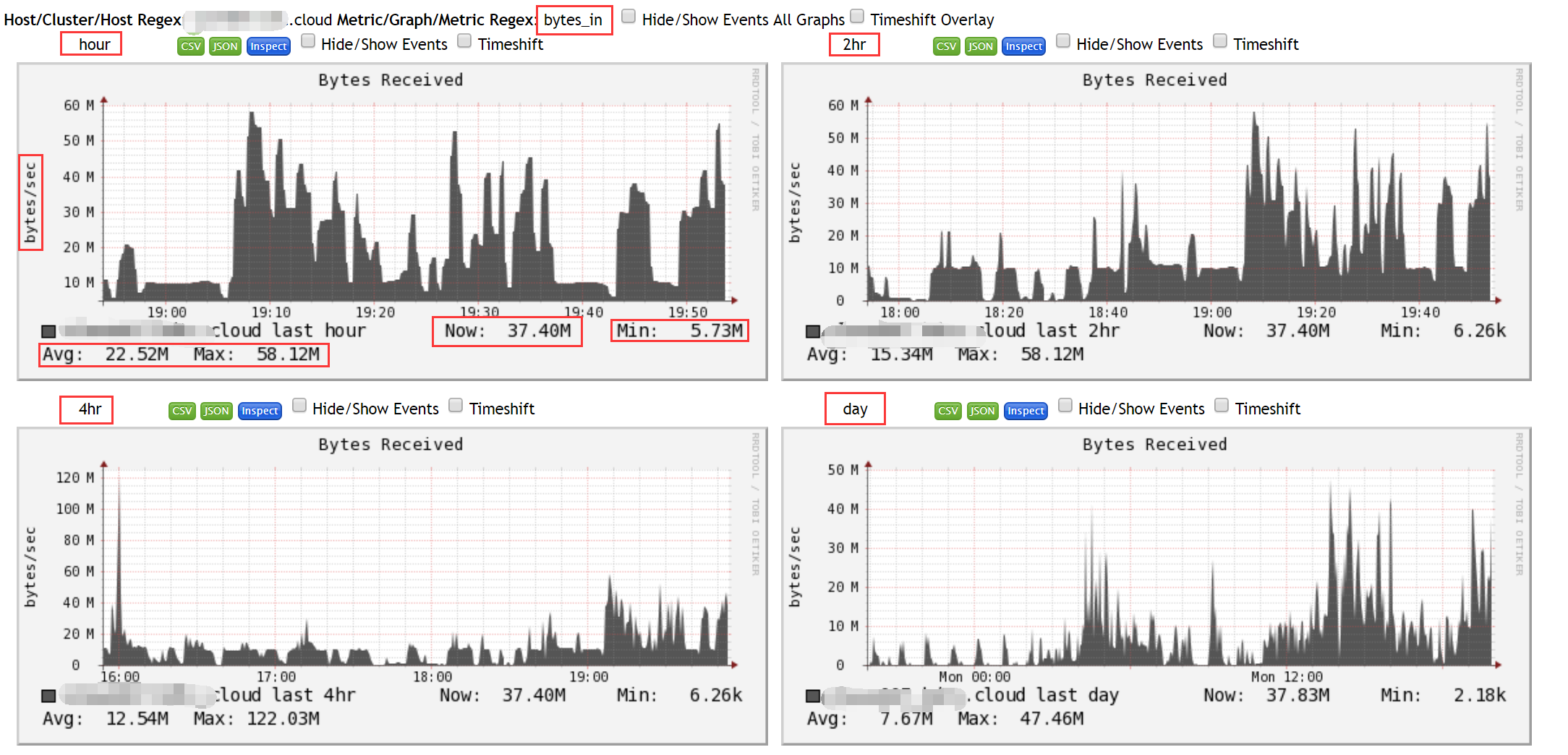
在这个图中,显示了监控项“bytes_in”的详细监控数据,从图中可以看出,分别显示了1个小时、2个小时、4个小时、1天、1周、1个月、1年的数据状态统计。
监控项“bytes_in”表示每秒收到的字节数,它有四个值,分别是“Now”、“Min”、“Avg”、“Max”,分别表示现在收到的字节数、最小字节数、平均字节数和最大字节数。
这里又说到了监控项,那么ganglia web中默认包含了很多监控项,了解每个监控项的含义对于读懂ganglia web曲线图非常重要,那么这些默认的监控项都代表什么含义呢,下面就详细介绍下每个监控项的含义。
二、ganglia默认监控项介绍
ganglia默认收集的监控项数据分为6大类,下面依次说明下每类监控项代表的含义。
1、cpu metrics
cpu_aidle:自启动开始CPU空闲时间所占百分比,单位是百分比
cpu_idle:CPU空闲,系统没有显著磁盘I/O请求的时间所占的百分比
cpu_intr :CPU参与I/O终端的时间所占百分比
cpu_nice : 以user level、nice level 运行时的CPU占用率,单位百分比
cpu_sintr :CPU参与I/O软中断的时间所占的百分比,单位百分比
cpu_steal :管理程序维护另一个虚拟处理器时,虚拟 CPU 等待实际 CPU 的时间的百分比。(Steal 值比较高的话,你需要向主机供应商申请扩容虚拟机。服务器上的另一个虚拟机可能拥有更大更多的 CPU 时间片,你可能需要申请升级以与之竞争。低 steal 值意味着你的应用程序在目前的虚拟机上运作良好。因为你的虚拟机不会经常地为了 CPU 时间与其它虚拟机激烈竞争,虚拟机会更快地响应。)
cpu_system: 系统进程对CPU的占用率。
cpu_user: 以user level运行时的CPU占用率
cpu_wio: 用于进程等待磁盘I/O而使CPU处于空闲状态的百分比
2、mem_buffers metrics
mem_buffers: 缓冲(buffer)内存容量
mem_cached: 缓存(cache)容量
mem_free: 可用内存容量
mem_shared: 共享内存容量
swap_free: 可用交换内存容量
3、disk metrics
disk_free:所有分区的总空闲磁盘空间。 disk_total:总存储空间。 part_max_used:所有分区已经占用的百分比。
4、load metrics
load_fifteen:十五分钟平均负荷 load_five:五分钟平均负荷 load_one:一分钟平均负荷
5、network metrics
bytes_in: 每秒收到的字节数
bytes_out: 每秒发出的字节数
pkts_in:每秒收到的包数
pkts_out:每秒发出的包数
6、process metrics
proc_run:正在运行的进程总数 proc_total:进程总数
7、其它系统指标
os_release: 操作系统发布日期,字符串类型
gexec: gexec可用,布尔类型
mtu: 网络最大传输单位,整数型
location: 主机位置,字符串类型
os_name: 操作系统名称,字符串类型
boottime: 系统最近启动时间
sys_clock: 系统时钟时间,单位是时间
heartbeat: 上一次心跳发送时间,整数型
machine_type: 系统架构,字符串类型
三、Ganglia监控扩展实现机制
在默认情况下,Ganglia通过gmond守护进程收集CPU、内存、磁盘、IO、进程、网络六大方面的数据,然后汇总到gmetad守护进程下,使用rrdtools存储数据,最后将历史数据以曲线方式通过php页面呈现。但是很多时候这些基础数据还不足以满足我们的监控需要,我们还要根据应用的不同,扩展ganglia的监控范围。下面我们就介绍通过开发Ganglia插件扩展Ganglia监控功能的实现方法。
3.1、 扩展Ganglia监控功能的方法
默认安装完成的Ganglia仅向我们提供基础的系统监控信息,通过Ganglia插件可以实现两种扩展Ganglia监控功能的方法。
1、 添加带内(in-band)插件,主要是通过gmetric命令来实现。
这是通常使用的一种方法,主要是通过crontab方法并调用Ganglia的gmetric命令来向gmond输入数据,进而实现统一监控。这种方法简单,对于少量的监控可以采用,但是对于大规模自定义监控时,监控数据难以统一管理。
2、 添加一些其他来源的带外(out-of-band)插件,主要是通过C或者Python接口来实现。
在Ganglia3.1.x版本以后,增加了C或Python接口,通过这个接口可以自定义数据收集模块,并且可以将这些模块直接插入到gmond中以监控用户自定义的应用。
3.2、 通过gmetric接口扩展Ganglia监控
gmetric是Ganglia的一个命令行工具,它可以将数据直接发送到负责收集数据的gmond节点,或者广播给所有gmond节点。由此可见,采集数据的不一定全部都是gmond这个服务,也可以直接通过应用程序调用Ganglia 提供的gmetric工具将数据直接写入gmond中,这就很容易的实现了ganglia监控的扩展。因此,我们可以通过shell、perl、python等语言工具,通过调用gmetric将我们想要监控的数据直接写入gmond中,简单而快速的实现了Ganglia的监控扩展。
在Ganglia安装完成后,会在bin目录下生成gmetric命令。下面通过一个实例介绍一下gmetric的使用方法:
[root@cloud1 ~]# /opt/app/ganglia/bin/gmetric -n disk_used -v 40 -t int32 -u '% test' -d 50 -S '8.8.8.8:cloud1'其中:
-n,表示要监控的指标名。
-v,表示写入的监控指标值。
-t,表示写入监控数据的类型。
-u,表示监控数据的单位。
-d,表示监控指标的存活时间。
-c,用于指定ganglia配置文件的位置。
-S,表示伪装客户端信息,8.8.8.8代表伪装的客户端地址,cloud1代表被监控主机的主机名。
通过不断地执行gmetric命令写入数据,Ganglia Web的监控报表已经形成,如下图所示。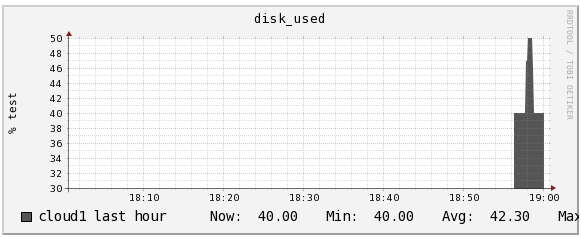
从图中可以看到刚才执行命令时设置的几个属性值在报表中都呈现出来了,例如disk_used、“% test”、cloud1等。同时,通过gmetric写入的监控数值,在报表中也很清楚地展示出来了。
在上面的实例中,我们通过执行命令的方式不断写入数据,进而生成监控报表,事实上,所有的监控数据都是自动收集的,因此,要实现数据的自动收集,可以将上面的命令写成一个shell脚本,然后将脚本文件放入cron运行。
假设生成的脚本文件是/opt/ganglia/bin/ganglia.sh,运行crontab -e,将此脚本每隔10分钟运行一次:
*/10 * * * * /opt/ganglia/bin/ganglia.sh最后,打开Ganglia Web进行浏览,即可看到通过gmetric命令收集到的数据报表。
3.3、通过Python插件扩展Ganglia监控
要通过Python插件扩展Ganglia监控,必须满足如下条件:
Ganglia 3.1.x以后版本
Python2.6.6或更高版本
Python开发头文件(通常在python-devel这个软件包中)
在安装Ganglia客户端(gmond)的时候,需要加上“--with-python”参数,这样在安装完成后,会生成modpython.so文件,这个文件是Ganglia调用Python的动态链接库,要通过Python接口开发Ganglia插件,必须要编译安装此Python模块。
这里假定Ganglia的安装版本是ganglia3.7.2,安装目录是/opt/app/ganglia,要编写一个基于Python的Ganglia插件,需要进行如下操作。
1、修改modpython.conf文件(Ganglia客户端)
在Ganglia安装完成后,modpython.conf文件位于/opt/app/ganglia/etc/conf.d目录下,此文件内容如下:
modules {
module {
name = "python_module" #python主模块名称
path = "modpython.so" #Ganglia调用Python的动态链接库,这个文件应该在Ganglia的安装目录的lib64/ganglia下面
params = "/opt/app/ganglia/lib64/ganglia" #指定我们编写的Python脚本放置路径,这个路径要保证是存在的。不然gmond服务无法启动
}
}
include ("/opt/app/ganglia/etc/conf.d/*.pyconf") #Python脚本配置文件存放路径2、重启gmond服务
在客户端的所有配置修改完成后,重启gmod服务即可完成Python接口环境的搭建。
3.4、实战:利用Python接口监控Nginx运行状态
搭建完Python接口环境成,只是实现Ganglia监控扩展的第一步,接下来还要编写基于Python的Ganglia监控插件。不过幸运的是,网上有很多已经编写好的各种应用服务的监控插件,我们只需要拿来使用即可。
大家可以从https://github.com/ganglia/gmond_python_modules
下载各种需要的Ganglia扩展监控插件,这里要下载的是nginx_status这个Python插件。下载完成的nginx_status插件的目录结构如下:
[root@cloud1nginx_status]# ls
conf.dgraph.dpython_modulesREADME.mkdn其中,conf.d目录下放的是配置文件nginx_status.pyconf,python_modules目录下放的是Python插件的主程序nginx_status.py,graph.d目录下放的是用于绘图的php程序。这几个文件一会都会用到。
对Nginx的监控,需要借助with-http_stub_status_module模块,此模块默认是没有开启的,所以需要指定开启,用于编译Nginx。关于安装与编译Nginx,这里不进行介绍。
1、配置Nginx,开启状态监控
在Nginx配置文件nginx.conf中添加如下配置:
server {
listen 8000; #监听的端口
server_name IP地址; #当前机器的IP或域名
location /nginx_status {
stub_status on;
access_log off;
# allow xx.xx.xx.xx;#允许访问的IP地址
# deny all;
allow all;
}
} 接着,重启Nginx,通过http://IP:8000/nginx_status 即可看到状态监控结果。
2、配置ganglia客户端,收集nginx_status数据
根据前面对modpython.conf文件的配置,我们将nginx_status.pyconf文件放到/opt/app/ganglia/etc/conf.d目录下,将nginx_status.py文件放到/opt/app/ganglia/lib64/ganglia目录下。
nginx_status.py文件无需改动,nginx_status.pyconf文件需要做一些修改,修改后的文件内容如下:
[root@cloud1 conf.d]# morenginx_status.pyconf
modules {
module {
name = ‘nginx_status’ #模块名,该文件存放于/opt/app/ganglia/lib64/ganglia下面
language = ‘python’ #声明使用Python语言
paramstatus_url {
value = ‘http://IP:8000/nginx_status' #这个就是查看nginx状态的URL地址,前面有配置说明
}
paramnginx_bin {
value = ‘/usr/local/nginx/sbin/nginx’ #这里假定Nginx安装路径为/usr/local/nginx
}
paramrefresh_rate {
value = ‘15’
}
}
}
#下面是需要收集的metric列表,一个模块中可以扩展任意个metric
collection_group {
collect_once = yes
time_threshold = 20
metric {
name = ‘nginx_server_version’
title = “Nginx Version”
}
}
collection_group {
collect_every = 10
time_threshold = 20 #最大发送间隔
metric {
name = “nginx_active_connections” #metric在模块中的名字
title = “Total Active Connections” #图形界面上显示的标题
value_threshold = 1.0
}
metric {
name = “nginx_accepts”
title = “Total Connections Accepted”
value_threshold = 1.0
}
metric {
name = “nginx_handled”
title = “Total Connections Handled”
value_threshold = 1.0
}
metric {
name = “nginx_requests”
title = “Total Requests”
value_threshold = 1.0
}
metric {
name = “nginx_reading”
title = “Connections Reading”
value_threshold = 1.0
}
metric {
name = “nginx_writing”
title = “Connections Writing”
value_threshold = 1.0
}
metric {
name = “nginx_waiting”
title = “Connections Waiting”
value_threshold = 1.0
}
}
3、绘图展示的PHP文件
在完成数据收集后,还需要将数据以图表的形式展示在Ganglia web界面中,所以还需要前台展示文件,将graph.d目录下的两个文件nginx_accepts_ratio_report.php、nginx_scoreboard_report.php放到Ganglia web的绘图模板目录即可。根据上面的设定,Ganglia web的安装目录是/var/www/html/ganglia,因此,将上面这两个PHP文件放到/var/www/html/ganglia/graph.d目录下即可。
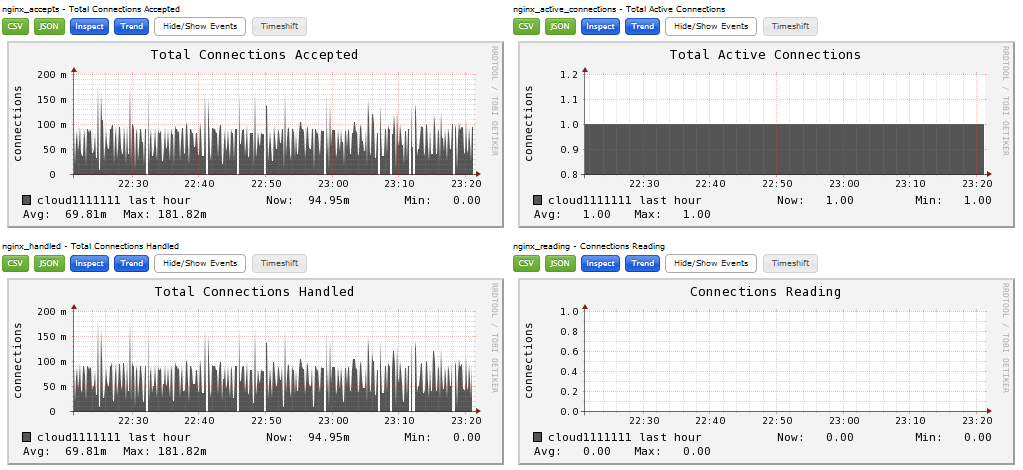
4、nginx_status.py输出效果图
完成上面的所有步骤后,重启Ganglia客户端gmond服务,在客户端通过“gmond–m”命令可以查看支持的模板,最后就可以在Ganglia web界面查看Nginx的运行状态,如下图所示。
四、Ganglia在实际应用中要考虑的问题
4.1、 网络IO可能存在瓶颈
在Ganglia分布式监控系统中,运行在被监控节点上的gmond进程消耗的网络资源是非常小的,通常在1~2MB之间,而gmond将收集到的数据仅保存在内存中,因此gmond消耗的网络资源基本可以忽略不记。但有一种情况,就是在采用单播模式下,所有gmond进程都会向一个gmond中央节点发送数据,而这个gmond中央节点可能存在网络开销,如果单播传输的节点过多,那么在中央节点上就会存在网络IO瓶颈。
另外,gmetad管理节点会收集所有gmond节点上的监控数据,同时Ganglia-Web也运行在gmetad所在的节点上,因此,gmetad所在节点的网络IO也会很大,可能存在网络IO瓶颈。
4.2、 CPU可能存在瓶颈
对于gmetad管理节点,它将收集所有gmond节点收集到的UDP数据包,如果一个节点每秒发送10个数据包,300个节点每秒将会发送3000个,假如每个数据包300字节,那么每秒就有近1MB的数据,这么多数据包需要的CPU处理能力也会增加。
gmetad在默认情况下每15秒到gmond取一次数据,同时gmetad请求完数据后还要汇总到xml文件,还需要对xml文件进行解析,如果监控的节点较多,比如1000个节点,那么收集到的xml文件可能有10~20MB左右。如果按照默认情况每隔15秒去解析一个20MB左右的xml文件,那么CPU将面临很大压力,而gmetad还要将数据写入rrd数据库,同时还要处理来自Web客户端的解析请求进而读rrd数据库,这些都会加重CPU的负载,因此在监控的节点比较多时,gmetad节点应该选取性能比较好的服务器,特别是CPU性能。
4.3、gmetad rrd数据写入可能存在瓶颈
gmetad进程在收集完成客户端的监控数据后,会通过rrdtool工具将数据写入到rrd数据库的存储目录。由于rrd拥有独特的存储方式,它将每个metric作为一个文件来存储,并且如果配置了数据采集的频率,gmetad还会为每个采集频率保存一个单独的文件,这就意味着,gmetad将metric值保存到rrd数据库的操作将是针对大量小文件的IO操作。假设集群有500个节点,每个节点有50个metric,那么gmetad将会存储25000个metric,如果这些metric都是每一秒更新一次,这将意味着每秒有25000个随机写入操作,而对于这种写入操作,一般的硬盘是无法支撑的。
4.4、ganglia使用过程中可能出现的问题
1、访问http://ip/ganglia/, 如果报下面的错误:

这是因为,没有修改默认的ganglia web配置文件conf_default.php里面“$conf['gweb_confdir']”的值,这个变量是指定ganglia web程序的安装目录,默认是“/var/lib/ganglia-web”,如果你不是放在这个目录下,那么就要修改这个值,这里我是将ganglia web程序放到了/var/www/html目录下了,所以要修改“$conf['gweb_confdir']”的值为“/var/www/html/ganglia”即可。
修改完成后,重新访问http://ip/ganglia/, 可能还会出现如下错误:
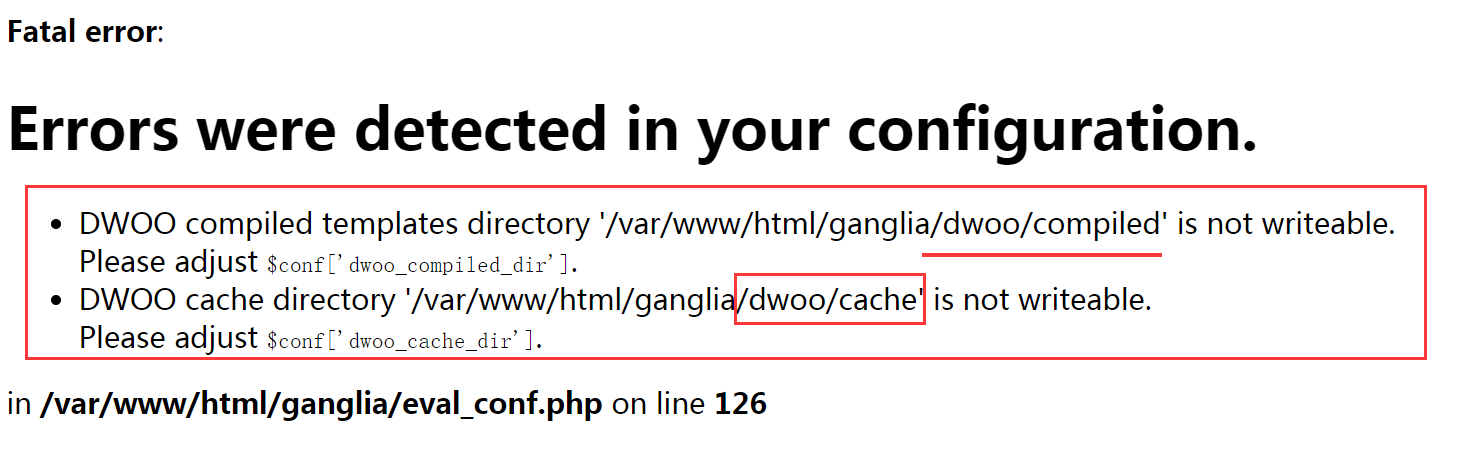
这个是因为没有写权限导致的,根据提示,首先创建这两个目录,然后做授权即可,操作如下:
[root@localhost ~]# mkdir -p /var/www/html/ganglia/dwoo/{compiled,cache}
[root@localhost ~]# chown -R apache:apache /var/www/html/ganglia/dwoo/{compiled,cache}
注意,这里将compiled和cache目录授权给了apache用户,这个用户是启动httpd服务的用户,如果是lamp架构,那么就看启动apache的是哪个用户,如果是lnmp架构,那么就看启动php-fpm的是哪个用户。
2、故障现象:
There was an error collecting ganglia data (127.0.0.1:8652): fsockopen error: Connection refused查看message日志:
localhost /usr/sbin/gmetad[14747]: RRD_create: creating '/var/lib/ganglia/rrds/__SummaryInfo__/diskstat_vda_writes.rrd': Permission denied
localhost /usr/sbin/gmetad[14747]: Unable to write meta data for metric diskstat_vda_writes to RRD根据日志提示,这是没有权限写rrds元数据导致的问题,默认配置rrds数据的路径在配置文件conf_default.php里面的如下变量中:
$conf['gmetad_root'] = "/var/lib/ganglia";
$conf['rrds'] = "${conf['gmetad_root']}/rrds";这是默认的路径,当然也可以指定自定义路径,不管指定什么路径,都要保证此路径有gmond进程的写权限,而gmond进程的启动用户在gmond.conf里面进行配置,默认是nobody用户,因此解决办法如下:
[root@localhost ~]# systemctl status gmetad
gmetad.service - Ganglia Meta Daemon
Loaded: loaded (/usr/lib/systemd/system/gmetad.service; disabled; vendor preset: disabled)
Active: inactive (dead)
[root@localhost ~]# chown -R nobody:nobody /var/lib/ganglia/rrds
[root@localhost ~]# systemctl start gmetad3、故障现象:
gmond服务启动后,节点也会出现对应图形,但是主机图里面没有曲线数值,图的下方提示:No matching metrics detected
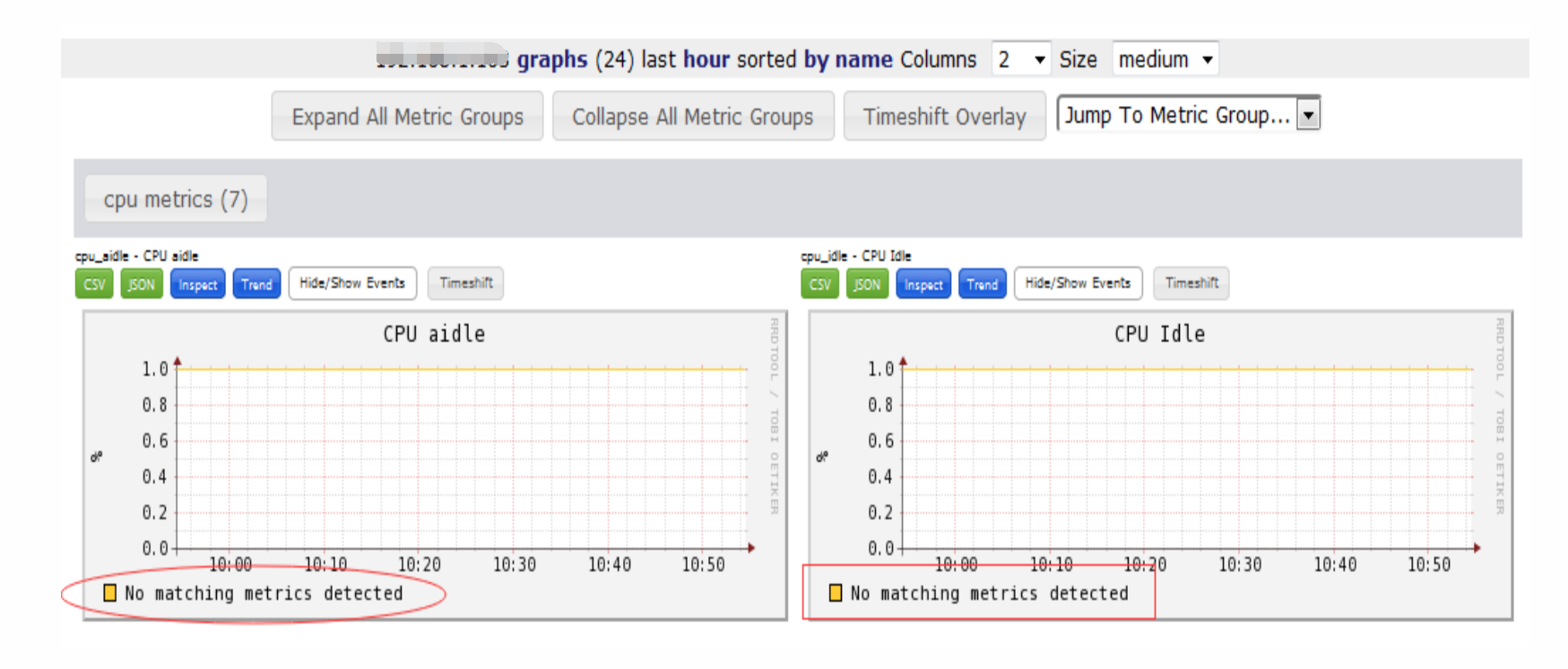
针对这个问题,可能的原因有三个:
(1)、安装步骤是否正确,是否缺少相关的目录
(2)、查看message日志,是否目录权限错误,尤其是/var/lib/ganglia/rrds/是否有权限。
(3)、被监控的节点是不是开了防火墙、selinux之类的操作。
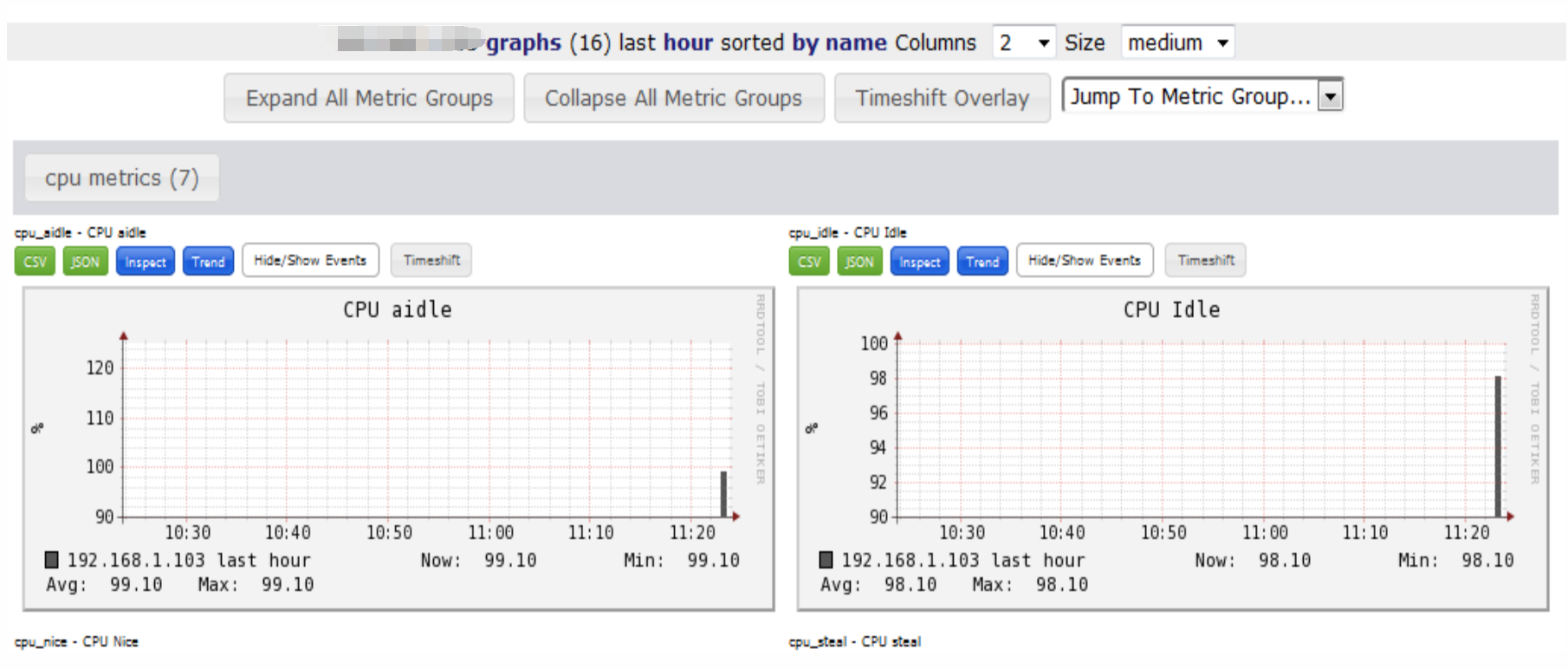
本例是因为entos7的firewalld没有关闭,下面是关闭防火墙服务后的效果图:
好吧,ganglia扩展监控就介绍到这里了,后面还有介绍ganglia与centreon的整合,实现更强大的分布式监控系统。
